 Какую-то часть страниц любого сайта поисковая система Гугл считает важными и помещает в основной индекс. Такие страницы участвуют в ранжировании по запросам и формируют поисковую выдачу. Но у Google имеется и дополнительный индекс, так называемые «сопли гугла» или «Supplemental Index», в который помещаются страницы сайта, которые алгоритм посчитал не важными, либо нарушающими правила и недостойными основного индекса по каким-либо причинам.
Какую-то часть страниц любого сайта поисковая система Гугл считает важными и помещает в основной индекс. Такие страницы участвуют в ранжировании по запросам и формируют поисковую выдачу. Но у Google имеется и дополнительный индекс, так называемые «сопли гугла» или «Supplemental Index», в который помещаются страницы сайта, которые алгоритм посчитал не важными, либо нарушающими правила и недостойными основного индекса по каким-либо причинам.
Каждая новая статья любого веб-сайта проверяется поисковой системой Google на предмет соответствия критериям основного индекса. При этом обсчитывается масса параметров и учитывается история ресурса. Если за сайтом уже были замечены те или иные нарушения, проверка производится более тщательно и риск попадания новых страниц в supplemental index растёт.
Чем больше страниц блога или сайта попадает в сопли, тем меньше трафика с гугла имеет ресурс, так как подобные страницы не участвуют в поиске. Часто причиной просадки трафика и потери позиций является именно массовый перевод страниц сайта из основного в дополнительный индекс за какие-либо нарушения. Задачей вебмастера является уменьшение количества страниц, попавших в дополнительный индекс.
---------------------------------------
Основные причины попадания страниц в сопли
- Дублированное содержание (дубли)
- Неуникальный контент
- Отсутствие Title, Descriptin
- Минимальное количество контента на странице
- Явное отклонение страницы от основной темы сайта
- Изменение структуры URL ресурса
- и т.д.
Проверка страниц сайта на сопли
Способы проверки сайта на наличие страниц в дополнительном индексе сильно разнятся, опишу только чем пользуюсь сам. Во-первых, посмотреть страницы в основном индексе можно с помощью следующего запроса в Гугл: site:ваш сайт/& То есть для этого блога запрос будет выглядеть таким образом: site:comp-on.ru/&
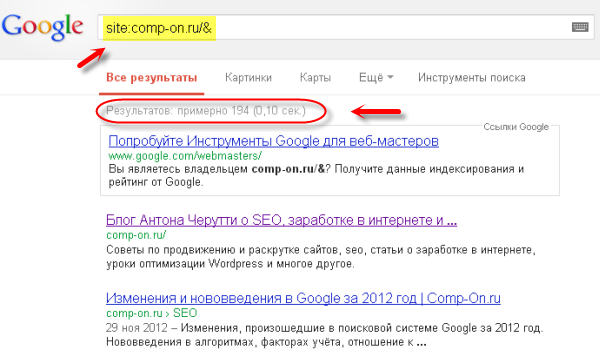
Основной индекс
Вы вставляете вместо comp-on.ru домен своего сайта соответственно. Как видим на картинке, по этому запросу найдено 194 результата, что примерно соответствует количеству опубликованных статей на этом блоге. Из этого можно сделать вывод, что почти все статьи блога находятся в основном индексе Гугла.
Для того, чтобы увидеть все страницы сайта:
site:ваш сайт
То есть для этого блога запрос будет — site:comp-on.ru
Разница между страницами в основном индексе и всеми проиндексированными страницами сайта это и будут сопли.
---------------------------------------
Теперь проверим на сопли случайный блог из Сети. Банально взял первый попавшийся блог inetrab.ru
Конструкция вида site:ваш сайт -site:ваш сайт/& — больше не работает!
Пользуйтесь определением основного и полного индекса. Как это сделать написано выше.
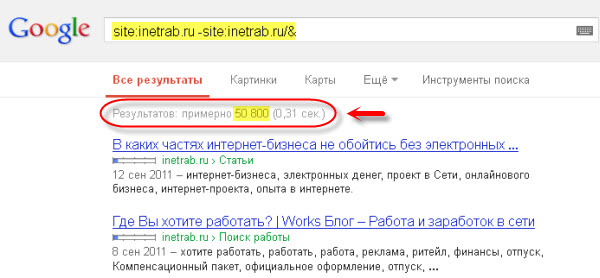
Проверка на дополнительный индекс
Результат — более 50 000 страниц (адресов). Я не углублялся в изучение этого сайта, но здесь скорее всего проблема с дублями контента, отсюда и такое количество страниц в дополнительном индексе. Можно предположить, что к этому сайту уже применяются санкции, либо они будут скоро применены, вплоть до исключения всего ресурса из основной выдачи Google.
---------------------------------------
Примерное соотношение страниц сайта, участвующих в основном и дополнительном индексе, можно увидеть с помощью RDS бара

Сопли в RDS
В процентах количество страниц сайта в основной выдаче, по отношению к общему количеству проиндексированных страниц.
---------------------------------------
 Проблема с сопливыми страницами сайта ещё и усугубляется тем, что робот посещает данные странички крайне редко, и даже исправив все нарушения либо полностью удалив эти страницы, можно ещё полгода ждать исправления ситуации, когда бот соизволит посетить эти урлы, а потом ещё некоторый период пока обновятся данные в кэше. И только после этого алгоритм начнёт оценивать ваш сайт с позиции того что нарушения исправлены. Для удаления из индекса Гугла ненужных страниц можно воспользоваться «инструментами для веб-мастеров» от поисковой системы Google.
Проблема с сопливыми страницами сайта ещё и усугубляется тем, что робот посещает данные странички крайне редко, и даже исправив все нарушения либо полностью удалив эти страницы, можно ещё полгода ждать исправления ситуации, когда бот соизволит посетить эти урлы, а потом ещё некоторый период пока обновятся данные в кэше. И только после этого алгоритм начнёт оценивать ваш сайт с позиции того что нарушения исправлены. Для удаления из индекса Гугла ненужных страниц можно воспользоваться «инструментами для веб-мастеров» от поисковой системы Google.
При наполнении сайта надо стараться, чтобы как можно большее количество страниц были качественными и попадали в основной индекс, а не уходили в сопли. Вовремя исправлять нарушения и недочёты.
Как я повторял уже много раз, каждое нарушение любого отдельно взятого сайта учитывается поисковиками и складывается в историю ресурса. Когда количество нарушений сайта переходит за какой-то определённый установленный рубеж — следует наказание, обычно в виде сильной пессимизации или бана. Не стоит доводить свой ресурс до таких проблем.
 Среди сеошников давно ходит байка о том, что у гугла нет никаких соплей да и сами представители этой поисковой системы якобы заявляли об этом. Однако с помощью запросов, которые были представлены в этой статье, данные утверждение легко опровергается. Никто не говорит, что в гугле это называется именно соплями, однако суть от этого не меняется — подобные страницы не участвуют в поиске, соответственно не приводят посетителей, и часто являются причиной пессимизации либо бана сайта. А называть это можно как угодно.
Среди сеошников давно ходит байка о том, что у гугла нет никаких соплей да и сами представители этой поисковой системы якобы заявляли об этом. Однако с помощью запросов, которые были представлены в этой статье, данные утверждение легко опровергается. Никто не говорит, что в гугле это называется именно соплями, однако суть от этого не меняется — подобные страницы не участвуют в поиске, соответственно не приводят посетителей, и часто являются причиной пессимизации либо бана сайта. А называть это можно как угодно.
Курс SEO для начинающих. Часть 3




 Категория:
Категория: 

У меня много «соплей» и почти все они — ссылки на картинки, вставленные в сообщения. Что же делать? Не убирать же их...
В сопли могут попадать урлы страниц, про ссылки на изображения ничего не слышал. Как определял?)
Определял, как ты написал. Кроме того у меня установлен RDS-бар. В основном — 166 страниц, в соплях — 170, а вообще всего на данный момент в индексе — 294 страницы. Получается, что в основном индексе по показаниям RDS на данный момент 53%. Нестыковка, но все же удручает, как много идет страниц ( а это урлы картинок и еще кое каких мелочей, связанных с работой плагинов) попадают в сопли. Может быть есть способ закрытия таких урлов (на картинки идут ссылки на медиафайлы и у тебя же такого не происходит!) от индексации вообще? Я не знаю такого способа.
А ты введи в поисковик site:comp-on.ru -site:comp-on.ru/& и потом нажми «повторить поиск» твои фиды высветятся более 400 раз. Тут все согласуется с показаниями RDS для твоего сайта. Но вот ссылок на картинки нет!! Парадокс.
твои фиды высветятся более 400 раз. Тут все согласуется с показаниями RDS для твоего сайта. Но вот ссылок на картинки нет!! Парадокс.
Может быть и правда — не заморачитваться и правы SEO-шники...
Ну ввёл site:comp-on.ru -site:comp-on.ru/& и нажал повторить, так там же написано под каждой позицией что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt». То есть эти страницы запрещены к индексации в роботсе, а почему гугл их показывает это уже вопрос к гуглу, раньше не показывал, спроси на ихнем форуме, может ответят)
Посмотрел кстати и твои сопли (дубли), советую дописать в роботс —
Disallow: /attachment/
как видишь у тебя во всех дублирующих сопливых урлах присутствует директория вложений /attachment/.
Да, это действительно так. Я внимательно просмотрел и свой сайт. Там все же более половины аналогичных страниц, которые запрещены роботс. Но есть и довольно много картинок.
А обращаться вряд ли стану. Как-то обращался по поводу основного индекса, дык там ответили, что его вообще нет- в RDS он на тот момент вообще исчез. С этим Гуглом сам черт не разберется(((
Ну а если дополнительного индекса нет что тогда показывает запрос — site:ваш сайт -site:ваш сайт/& Ведь он показывает для каждого сайта свой результат.
А у тебя на блоге банальные дубли, сопли, называй это как хочешь, суть то одна. Дубли же тоже не идут в основной индекс, или дублей тоже не бывает?)
Дубли у тебя вида страниц с вложениями —
_http://prt56.ru/seo/sozdanie-onlajn-konsultacii-na-sajte-prosto-i-besplatno.html/attachment/nnnn4
_http://prt56.ru/wordpress/nrelat-effektivnyj-plagin-dlya-svyazannyx-i-populyarnyx-soobshhenij.html/attachment/lll2
и все они в индексе а наплодить их при желании можно миллионы, потому и говорю тебе допиши в роботс —
Disallow: /attachment/
Disallow: /attachment/ — вставил. Теперь будем посмотреть. Только как долго все будет меняться...
Моментально они не исчезнут из индекса. Это долго, к тому же сопли гугл посещает крайне редко, я об этом писал в статье. Правда можешь помочь хухлю выкинуть это дерьмо из индекса через вебмастер гугла — оптимизация — удалить URL адреса.
Будем работать. Спасибо!
Да, работать нужно или никаких результатов не будет вообще. У меня продолжается бесконечная война с ленью)
У меня вообще непонятка. В индексе по RDS бару 2760 (9%), а через поиск по формуле в соплях вообще 1 страница и то, закрыта в robots.txt. Все дубли в robots позакрывал.
Зато есть сайт, где в robots три строки и там 86% в основном индексе.
Вот, как сделать, чтобы не показывал Гугл в 10 раз больше в индексе, чем Яша? Вот у тебя разница не большая.
Что значит User-agent: ia_archiver у тебя в файле?
rds берёт данные точно так же как написано в статье — нажми на циферки страниц в соплях. Тут ещё от самого сайта зависит, у меня на сайтах на чистом html — 98-100%, так как дублям просто неоткуда браться, дубли ведь в основном движки генерируют а нет движка — нет дублей и соплей тоже)
По rds у тебя да, много страниц в гугле показывает. А если проверить через запрос site:ваш сайт/& как в статье выше написано сколько результатов?
Кстати можешь ещё посмотреть в вебмастере гугла — состояние — статус индексирования — расширенные данные — может так что то прояснится?
User-agent: ia_archiver — запрет доступа для бота вебархива.
По запросу с & — 241 страница (примерно, как в Яндексе), а в инструментах всего проиндексировано 4 706, причем запрещено в robots — 4 827. А вот в Вебмастере Яши загружено 5112. Короче, до фига у меня страниц на сайте. Думаю это из-за комментариев, их у меня почти 5 000.
Проверил в Вебмастере, они разрешены к индексации, хотя три директивы стоит запрещающих комментарии. Только, когда сейчас поставил Disallow: /*#comment, стал показывать запрет. Получается так надо оставить?
Ну если предыдущие правила не запрещали индексацию комментов то наверное да)
НЕ удалил эту конструкцию. Знак # — это же закоментирывовывает строку, то есть /*#comment аналогично /*. А это значит запретить всю индексацию. Если оставить /*comment, то комментарии не закрывает. У меня так и стояло, а теперь убрал, так как есть статья где в URL есть слово comment и она запрещена для индексации. Хорошо, что заметил сейчас.
Вот теперь вопрос, как закрыть урлы комментов, которые имеют в конце примерно такую конструкцию html#comment-37562
Олег, да я фиг знает. Попробуй
Disallow: /*comment
или
Disallow: /*comment-
На счёт значка # в урле это не имеет отношения к комментированию по моему.
Значок # обозначает, что все, что после него не учитывается, т.е. там можно просто служебные комментарии текстом писать. А приведенные тобой варианты пробовал, не закрывают. Только статью закрывают нужную. Ладно, будет время поиграюсь.
Олег, что такое # в коде я в курсе, только к роботсу и к урлам это мне кажется никакого отношения не имеет.
Попробуй поставь в Вебмастере в любой строчке # после первого слэша и перед любым правилом и проверь даже главную страницу.
Ничего не понял... «поставь в Вебмастере в любой строчке # после первого слэша» Говори сразу суть. Кстати попробуй поставить вместо # другой любой знак типа &, *, ^ — изменится что нибудь или нет?
Я имел ввиду в разделе Анализ robots.txt, изменить таким образом robots и проверить любую страницу.
Ну да, всё верно, типа тогда работает запрещающее правило
Disallow: /
даже не знал что в роботсе знак «#»так обрабатывается.
Прикинь, если бы я так оставил. Хорошо, что проверил другие страницы.
Это да. Век живи — век учись. Кстати правило Disallow: /*#comment ты сам выдумал, я тебе его не советовал. Я советовал попробовать для закрытия соплей
Disallow: /*comment
или
Disallow: /*comment-
Просто эти два не работают, вот и придумал. Хотя по идее должны же работать.
Не, если не работают то и не должны. А не работают потому что перед comment в урлах нет слэша наверно.
Вот тут есть немного — _http://www.armadaboard.com/topic44806.html?tape
Типа говорят решётка это не дубль. Типа поисковикам на решётки в урлах наплевать, они ставятся для браузеров, типа якорей.
Ну и ладно. Только не понятно, почему тогда столько страниц в индексе Гугла?
Да фиг знает, у гугла с этим делом всегда какие то непонятки были. Если хочешь спроси на форуме гугла, там есть пара толковых человек.
Никогда сопли не мешали, так для справки интернет магазин или форум где 10000+ страниц редактирование их что бы они попали в основную выдачу не реально да и конкретную позицию ищат единицы нафига мне корректировать их для основной выдачи, бана за это никогда не получал. на некотрых сайтах 1-5% не соплей ПР присваивается ПР трафик с поисковиков стабильный проблем нет.
Мешают не сопли, а попадание страниц в дополнительный индекс. А если б не соплей было не 1-5%, а например 80%, то может трафика было бы больше?)
Про магазины и т.д. отдельный разговор, я их здесь вообще не касался, разговор про статейные сайты.
Попробовала метод — не увидела разницу в выдаче разницу между запросами:
site:http://veni.com.ua Результатов: примерно 285 (0,16 сек.)
site:http://veni.com.ua -site:http://veni.com.ua/&, Результатов: примерно 286 (0,20 сек.)
А если смотреть в RDS бар — то индекс 22%
Что я не так делаю?
Попробуйте оформить эти запросы как написано в статье — то есть без протокола http. И вообще меньше зацикливайтесь на соплях, это не так важно.
Попробовала.
По запросу site:veni.com.ua -site:veni.com.ua/&,
Результатов: примерно 287 (0,21 сек.)
Все выдачи внешне выглядят одинаково, по крайней мере первые топ 10, дальше не сравнивала. Странно все это, почему у других метод работает, а у меня нет.
site:veni.com.ua/& — 61
site:veni.com.ua -site:veni.com.ua/& — 0
А если смотреть в RDS бар — то индекс 22%
Кликнете по цифре 22% в RDS и узнаете каким запросом он определяет страницы в основном индексе.
Я вот что хочу вам сказать — гугл индексирует всё подряд, вплоть до урлов которые запрещены к индексации в robots.txt. Потом лишние страницы выкидывает и через какое то время опять вносит их в индекс. На этом блоге процент страниц в основном индексе меняется примерно от 35 до 85% а количество страниц в индексе от 200 до 800.
Только подал сайт на индексацию и сразу результат — гугл проиндексировал только главную страницу и сразу в сопли. Почему так? Контент уникальный, объём не маленький. Вот адрес _http://bodybuilding.drfarm.ru/
Виталий, с чего ты взял что страница в соплях?
Ка посмотреть 1-2 тренинги:
«Курс SEO для начинающих. Часть 3»
половина в соплях и что теперь делать?
Рама, ничего не делать.
Проверял индексацию сайта на _http://xseo.in/indexed и там только одна страница и то в дополнительном индексе была, а сейчас одна в основном и 143 в дополнительном. Это нормально?
Чушь всё это.
1) RDS показывает 1820 (27%). Всего 458 статей + главная страница, страницы несколько разделов. Остальное теги — их не отключал, так как по ним есть переходы. Кто-то советовал отключить, кто-то напротив, так как сайт с уникальными статьями (свои + переводы). Некоторые страницы тегов в поиске.
С этим надо что-то делать?
2) И подскажите, пожалуйста. Добавлена в robots.txt строка — Disallow: /*?*
При этом иногда индексируются страницы подобного вида и в гугле и в яндексе: _http://www.worldbeer.org/news.html?start=10
Неправильно правило написал или это как раз тот случай, про который Вы выше написали, что google добавляет всё подряд, потом выкидывает и снова может добавить?
1. Если контент качественный и уникальный то можно ничего не делать. Посмотрите процент страниц в основном индексе гугла на других сайтах и сравните со своим.
2. Проверьте правильность директивы в яндекс вебмастер — Настройка индексирования — Анализ robots.txt
1) По процентам 491 страница в поиске, а по гугл-вебмастеру 464 статьи из 476 проиндексировались, остальное — видимо теги.
2) Спасибо за подсказку — не видел раньше кнопки проверить.
Пишет по поводу этих страниц — запрещен правилом /*?*, значит все правильно. Только не понятно зачем они попадают в поиск.
Андрей, посмотрите исходный код своих страниц, у вас всё закрыто в noindex. Открывающие теги есть а закрывающих нет. Закрывающий тег должен выглядеть так —
<!--/noindex-->На счёт страницы _http://www.worldbeer.org/news.html?start=10 она в гугле имеет пометку «Описание веб-страницы недоступно из-за ограничений в файле robots.txt.»
если коротко то роботс запрещает сканирование, а метатег ноиндекс индексирование, позволяет очистить хлам из индекса в гугле, роботс же управляет сканированием т.е. доступом бота к документу с оговоркой, что в любой момент может появиться ссылка на урл и если урл запрещен в роботсе он появится в индексе с пометкой о запрещении т.к. бот не смог его просканировать и понять выкинуть его из индекса или оставить
Спасибо за объяснения по роботсу и спасибо большое за найденную ошибку с индексом — не могу понять, как можно было так ошибиться и не закрыть тег везде) Добавлял недавно, надеюсь ничего не испортил.
Исправляйте а то яндекс выкинет весь ваш контент из индекса.
Я написала в поисковике как у вас написано и получила ответ:"Ничего не найдено из 2 поисковиков", Вы видимо здесь пошутили.
Ага, я вообще шутник. Может быть вы забивали как написано —
site:ваш сайт/& не заменяя «ваш сайт» на адрес своего сайта?
Совет — меньше заморачивайтесь с соплями и больше с качеством контента.
Даже такая строка в гугле уже ничего не выдает:
site:comp-on.ru -site:comp-on.ru/&
Антон, проверь сам. И из-за соплей гугл погубит любой качественный контент. Проверено!
Интерфейс гугла изменился, эта ссылка больше не работает. Пользуйтесь основной выдачей — site:comp-on.ru/&
результаты по запросу “site:http://сайт.ru/&” минус результаты по “site:http://сайт.ru/” это и будут сопли.
спасибо за плагин, проаналаизировал свой сайт -просто катастрофа. 6% показывает всего в основной выдаче. Но у нас на портале порядка 40000 страниц, в ручную не реально проверять. К кому можно обратиться, где этот процесс оптимизирован и автоматизирован?
Еще раз спасибо за блог, Антон -прям подсел на него)
Сергей, лучше всего обратиться к знающему оптимизатору например на любом seo форуме
Впервые услышала про «сопли» и проверила свой сайт- у меня их 2/3. Не под фильтром гугла 29%. Понятно, что плохо, сейчас начну изучать вашу статью -может получится что-то исправить. Спасибо.
Появился вопрос. Не поскажете почему страницы поддомена в «соплях» и можно ли их убрать?
Татьяна, гугл может убирать в сопли всё что захочет. Наверно страницы вашего поддомена он считает не важными. Либо содержащими дубли или ещё что ему не нравится.
Там вообще ничего нет, он для опытов. Я не понимаю почему и как основной и поддомен связвны.
Может у меня что-то не так на основном?
Татьяна, тем более если там ничего нет и он для опытов то зачем и что там гуглу индексировать? Поддомен по определению связан с основным сайтом на то он и поддомен основного домена.
Так зачем же он в «сопли» их повесил? Зачем-то же он эти страницы проиндексировал и теперь они портят общую картину?
Я понимаю, что за логику гугла Вы не отвечаете, но хотелось бы узнать, можно ли это исправить/убрать. Спасибо.
тогда закройте поддомен от индексации. И удалите ненужные директории из индекса. Это делается в инструментах для вебмастеров google —
На главной странице Инструментов для веб-мастеров выберите нужный сайт.
В меню слева выберите Индекс Google, а затем – Удалить URL-адреса.
Нажмите Создать запрос на удаление.
Укажите URL каталога, который необходимо удалить из результатов поиска, и нажмите кнопку Продолжить.
Обратите внимание, что учитывается регистр: URL должен содержать те же символы и в том же регистре, как и на сайте.
Если вы хотите удалить весь сайт, оставьте это поле пустым.
Выберите Удалить каталог.
Нажмите кнопку Отправить запрос.
Большое спасибо за подробный ответ!
Дубли это полный треш. Яндекс молодец, культурный и воспитанный робот. Запретили в robots.txt туда то не лезть, он и не лезет, а Гоголь этот везде свой нос сует!
Треш трешем а отслеживать всё равно надо. Гугл всё гумно собирает, даже где закрыто.
Подскажите, почему так мало страниц в основной выдаче? 10% -нет. Что можно изменить, посоветуйте.
В статье выше всё написано что нужно делать.
Здравствуйте, Антон! При проверке site:lys-eco.com-site:lys-eco.com/& гугл не находит ни одного документа, такое может быть? Я сомневаюсь, так как дубли страниц находит SEO lib иXtool. Не могу понять в чем дело. Может Вы что-то подскажете. Спасибо.
Приветствую. Предложенная конструкция кажется прекратила работать.
Используйте такое —
общий индекс — site:lys-eco.com
основной индекс — site:lys-eco.com/&
Вставлять в поисковую строку гугла а не в адресную строку браузера.
К сожалению и так не работает
Татьяна, всё работает. Откройте эту ссылку
Вы наверно в адресную строку вбивали а не в гугл.
В очередной раз зашла к вам, Антон, после ажиотажа на блоге Борисова. Его последней статьи про удаление соплей из индекса.
Не буду распространяться про особенности его инфо-бизнеса «с душком»(ИМХО), тем более, что вполне адекватные комменты Борисов всё-таки удаляет, если они не в стиле «спасибо, мой гуру, может еще чего подскажешь, а то как же мы без тебя»)))
Вопрос вот в чём. Хотелось бы узнать ваше мнение о сео-плагине от Йоаста. Там есть много различных функций, в том числе удаление страниц реплитуком, возможность закрытия от индексации отдельных страниц, рубрик... Много всего
У меня он стоит с начала года, не скрою — довольна, и судя по данным из я-вебмастера и вебмастера гугла, количество «соплей» уменьшилось значительно.
Или всё же дело не в плагинах, а в состоянии сайта в целом, в комплексе, так сказать?
Юлия, статью Борисова не читал, так что ничего сказать не могу.
Плагин WordPress SEO by Yoast в общем то многие хвалят. Я его не использовал. Какое он оказывает влияние на сопли не знаю.
Спасибо за ответ, отдельно показывают оба варианта, а в формуле нет.
Чисто арифметически цифру можно вывести, но она на порядок отличается от той, которую показывают при проверке на ссылки сервисы.
В статье выше я написал — Конструкция вида site:ваш сайт -site:ваш сайт/& — больше не работает!
Если вы больше верите сервисам чем гуглу то ориентируйтесь на них. Никаких проблем.
Конечно гуглу верю больше, тем более, что от его реакции зависит посещаемость.
Тут бы найти причину и устранить ее. Спасибо за ответы, давно уже ищу как решить проблему, но пока безрезультатно.
Причину чего? Посещаемость идёт не только с гугла но и с других поисковиков.
Причину большого количества дублей страниц в индексе.
Мельком глянул у вас пагинация индексируется, лучше закрыть. Потом редирект нужно сделать чтобы адреса страниц слешем заканчивались и т.д.
Читайте это и делайте как написано — /dubli-stranits-poisk-udalenie-dubley/
Ваши страницы — _https://www.google.ru/search?hl=en&q=site:lys-eco.com/%26&gws_rd=ssl#hl=en&newwindow=1&q=site:lys-eco.com/%26&start=50
Англоязычный сайт сперва в основном индексе, а через недельку весь ушёл в дополнительный. Правда тексты я переводил с русских сайтов, через гугл переводчик. Даже если текст, где-то плохо читабелен, то как это может понять поисковый робот?
Ты наверно машинным переводом переводил. А что ты хотел чтобы тебя в топ поставили?)
У меня со слешем нет, только без него, я так поняла, что главное, чтобы что-то одно из них было. А вот страницы сайта открываются по адресу с www и без www -проблема.
Буду изучать вашу статью, а то пока не всё до конца поняла и про пагинацию не нашла.
Ваша статья наверное самая толковая из всех, что я по этому поводу раньше читала. Спасибо, что отвечаете на вопросы.
Пагинация это страницы вида — _http://lys-eco.com/page/14
Закрываются правилом Disallow: */page/* в файле robots.txt
Просто допишите и всё. Это дубли.
Как решить проблему с www и слешем подробно описано в этой статье —
/dubli-stranits-poisk-udalenie-dubley/
Чем больше читаю, тем глупее вопросы возникают. С www , например —
Еще раз всё перепроверила и вижу, что с WWW перенаправляется на без него ( не дублируется). А в настройках вижу, что стоит выбор зеркала на усмотрение робота. И вот мой вопрос -нужно ли в этом случае указывать основным без WWW?
Спасибо.
Не знаю про какой сайт вы говорите но тот что у вас в подписи с www на без www не редиректится.
Да, тот который в подписи. Не понимаю, как такое может быть, но я сколько не задаю с www открывается без www. Почему у Вас не редиректится?
Тут вроде бы и неправильно задать нельзя, просто голова идет кругом.
Я не знаю как вы задаёте адрес но я проверяю так — открываете свои сайт, в адресной строке браузера (вверху) дописываете www перед доменом сайта чтобы получилось _www.lys-eco.com. Нажимаете Enter. Открывается страница с адресом _www.lys-eco.com то есть никакого редиректа нет.
Спасибо за терпение. Очистила кеш и теперь так как Вы говорите — редиректа нет.
Буду работать над этим. С Яндексом все получилось, а гугл просит подтверждение прав, хотя я их подтвердила при регистрации. Что ему нужно, не понимаю.
Татьяна, вам вообще нужно всё это?
Ну подтвердите ещё раз или снова кэш очищайте. Что то у вас много проблем с браузером. Если работаете в каком нибудь хроме выкиньте его на помойку.
Так точно, в хроме.
Работайте в Firefox. Многие проблемы отпадут.
Приветствую! Столкнулся с таким: на сайте страница, которая в «соплях» есть в выдаче гугла. Нонсенс? Хотел бы услышать ваше мнение. Спасибо!
сайт что в подписи под агс так что тебе не о соплях нужно думать.
Спасибо за статью, но у меня никак не получается увидеть страницы, которые в соплях гугла. На первой странице поиска показывает количество всех страниц, а если перехожу на 10-ю, остаются только те, что в основном индексе. Антон, подскажи пжл, как увидеть урлы страниц в доп. индексе?
Можете проверить тут — xseo.in
вбиваете урл в «проверка индексации сайта»
внизу будет показано сколько страниц в в supplemental выдаче Google.
сnраницы в основной выдаче можно проверить запросом в гугл — site:yurisuhanov.ru
Спасибо большое за такой быстрый ответ, а можно как-то узнать, какие именно страницы находятся в supplemental?
страницы в основной выдаче запросом в гугл — site:yurisuhanov.ru/&
сопли не знаю. rds бар показывает что у вашего сайта из подписи 81 страница в индексе яндекса и 408 страниц в индексе гугла. в основном индексе 18% проиндексированных гуглом страниц.
У меня показывает еще меньше 15%.
Интересная ситуация: когда вручную удаляла страницы с 404 ошибкой из индекса, % страниц в основном индексе резко повышался, несоизмеримо с количеством удаленных страниц. Но потом опять постепенно падал, и с каждым днем все больше и больше.
Еще недавно было чуть больше 200 страниц в индексе — уже больше 400, хотя добавила всего пару уникальных статей (сайт новый).
Хотела проанализировать, что за страницы вне основного индекса. Жаль, что нет такой возможности(
надо искать дубли посмотрите ещё здесь — здесь
сайт добавлен в вебмастер тулс гугла? там ещё можно посмотреть страницы в индексе. а то все эти плагины ошибаются часто бывает.