 Думаю, многим известно что поисковые запросы это основа большинства статейных сайтов и блогов. На основе запросов поисковые системы определяют смысл текста на странице и его место в поиске.
Думаю, многим известно что поисковые запросы это основа большинства статейных сайтов и блогов. На основе запросов поисковые системы определяют смысл текста на странице и его место в поиске.
Если вы напишете статью про ключевые слова и ни разу не употребите в тексте эту фразу, то вряд ли она попадёт на высокие позиции по данному запросу. Подбирать ключевые слова можно вручную или пользоваться программами типа Slovoeb, упрощающими поиск, определение частотности и сортировку запросов.
Рассмотрим подбор запросов для отдельно взятой статьи в программе Slovoeb
Установка и настройка Slovoeb
При первом запуске создаём новый проект. Проект — это файл, в котором будут храниться все данные. Проект можно сохранять, закрывать, открывать снова и дополнять новыми данными.
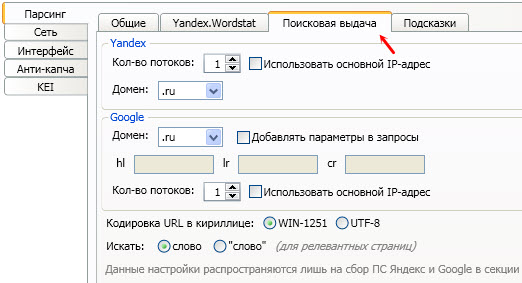
И настройки на вкладке «Поисковая выдача»
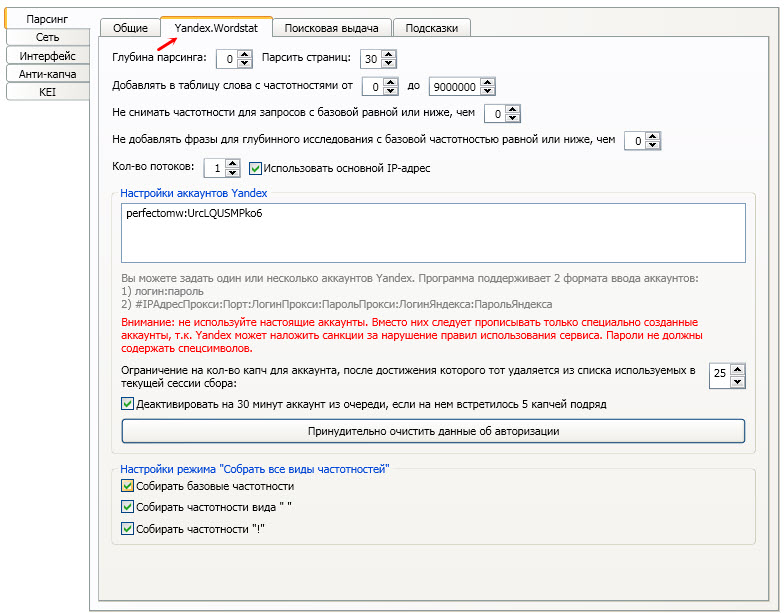
Остальные настройки не обязательны, подойдут дефолтные на первое время, разберётесь с ними по ходу работы в Slovoeb. Скажу лишь, что на вкладке «Анти — капча» в настройках можно добавить ключ Antigate для распознавания капчи и есть возможность работать в программе через прокси.
Все активные клавиши программы расположены сверху в интерефейсе (кликабельно).

1. Кнопка «Регионы Yandex.Wordstat» — выбираем нужный регион из списка, по которому будет производиться парсинг (если нужно). Снизу сохраняем изменения.
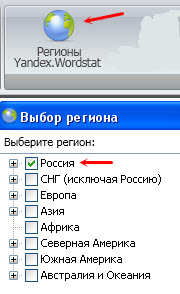
2. Левая колонка Yandex.Wordstat. Нажимаем на кнопку и добавляем ключевые слова. Чтобы было понятнее, я добавил только одну фразу для одной статьи. А вообще запросы можно добавлять вручную или загружать из файла (клавиши снизу). Собственно, это и есть главный инструмент программы Slovoeb. Вписываем запросы и начинаем парсинг по кнопке «Парсить с Яндекс Wordstat». По завершении операции все найденные ключи и их базовая частотность отображаются в программе.
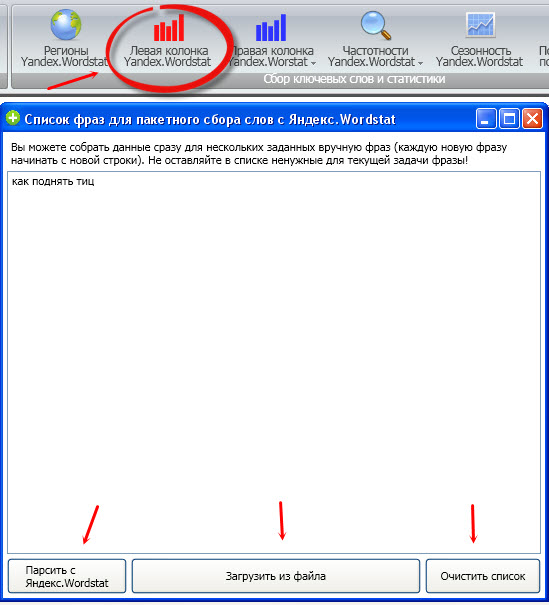
3. Правая колонка Yandex.Wordstat. То, что показывается в вордстате справа от основной колонки. То есть что ищут пользователи вместе с основным запросом. Иногда попадаются неплохие ключи. Вставляем на парсинг те же ключевые фразы, что и в предыдущем случае.
4. Частотности. Активируем кнопку и выбираем тип частотности, который хотим собрать. Базовая частотность, частотность "" и точное соответствие («!»).
5. Сезонность. Проверяем поисковые запросы на сезонность.
6. Поисковые подсказки. Это то, что подсказывают нам под окном поиска в поисковых системах при вводе запроса. Полученные таким образом ключи тоже можно использовать.
7. Kei. Показатель конкуренции. Сколько документов находится в поиске по данной ключевой фразе. Обычно чем больше документов, тем выше конкуренция.
8. Стоп-слова. Запросы с этими словами не учитываются при парсинге. Список стоп-слов задаётся вручную, либо из файла или буфера обмена.
9. Остановка работы программы. Если кнопка горит красным цветом значит идёт парсинг.
Работа с программой Slovoeb
Как было показано выше, добавим один запрос «как поднять тиц» по кнопке «Левая колонка Yandex.Wordstat» и нажмём «Парсить с Yandex.Wordstat» внизу. Если надо добавляем не один, а сразу несколько запросов. По заданному запросу программа нашла 23 ключа
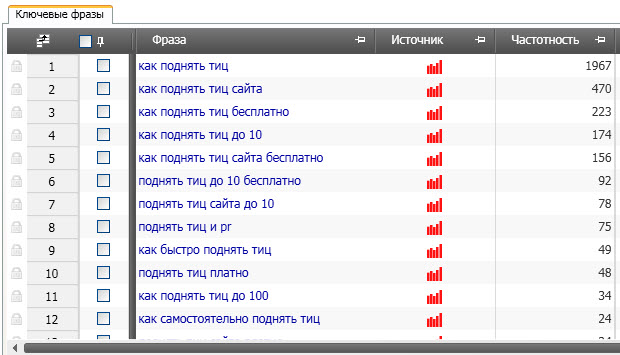
Сразу стоит удалить ненужные кеи, которые не подходят по смыслу и не релевантны. Отмечаем их галочками и на вкладке «Данные» (сверху) кликаем на «Удалить фразы».
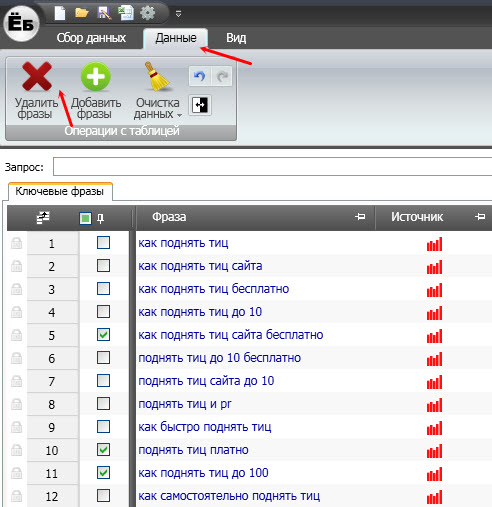
Для получения дополнительных результатов надо прогнать наш запрос по «Поисковым подсказкам» с помощью соответствующей кнопки. Алгоритм действий такой же как и «Левая колонка Yandex.Wordstat».
Теперь проверяем точную частотность запросов («!»). То есть сколько раз за месяц вводили в поиск именно этот запрос без изменений. Парсинг начинается автоматически при выборе нужной частотности.
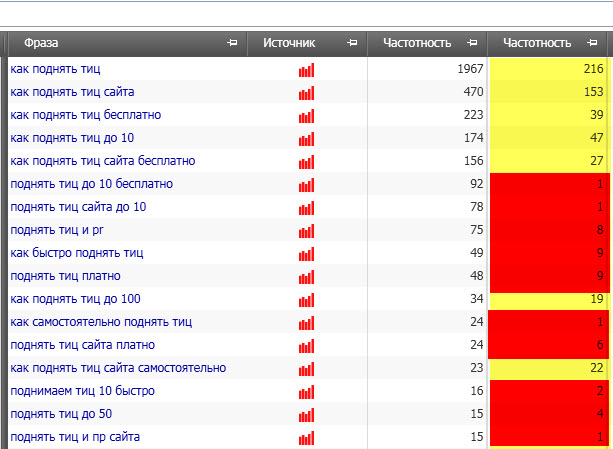
![]() Получаем данные по точной частотности (жёлтая колонка). Отсеиваем ключи с совсем низкой частотностью (красные), хотя для разных видов запросов этот порог может быть разным. Запросы с небольшой частотностью, как правило, имеют низкую конкуренцию, но они тоже дают трафик и их можно использовать в статьях. При необходимости проверяем конкуренцию и сезонность. С остальными запросами работаем дальше, отбираем подходящие и используем их при написании статьи.
Получаем данные по точной частотности (жёлтая колонка). Отсеиваем ключи с совсем низкой частотностью (красные), хотя для разных видов запросов этот порог может быть разным. Запросы с небольшой частотностью, как правило, имеют низкую конкуренцию, но они тоже дают трафик и их можно использовать в статьях. При необходимости проверяем конкуренцию и сезонность. С остальными запросами работаем дальше, отбираем подходящие и используем их при написании статьи.
В этой статье, для наглядности, описан подбор запросов по одной ключевой фразе для одной статьи. При составлении семантического ядра для целого сайта мы будем парсить уже не по одному, а по множеству запросов и ключей на выходе будут тысячи. Slovoeb поможет быстро их обработать.
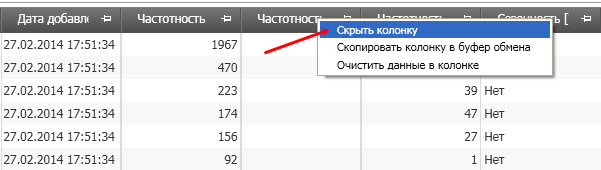
![]() Ненужные колонки в таблице легко убираются с помощью ПКМ по заголовку столбца и выбора действия «скрыть колонку»
Ненужные колонки в таблице легко убираются с помощью ПКМ по заголовку столбца и выбора действия «скрыть колонку»
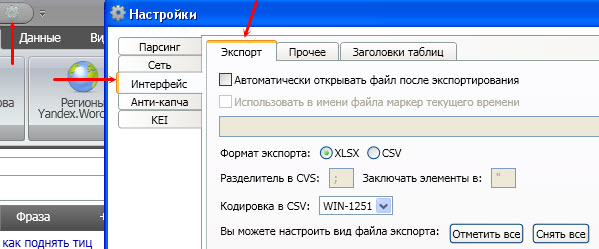
![]() Данные легко экспортируются в формате xlsx и csv.
Данные легко экспортируются в формате xlsx и csv.
----------------------------------------------------------------------------------------------------




 Категория:
Категория: 

Спасибо, Антон! А то работала с этой программойраньше, а потом она обновилась, изменилась и запуталась в ней. Теперь понятно.
Купила Кей Коллектор, а можно и про нее инструкцию сделать, если будет время и желание? Была бы вам признательна.
Виктория, не за что, я подумаю над этим вопросом) Собственно, принцип действия у этих программ одинаков однако KK имеет больший функционал которого нет в slovoeb.
Спасибо, что подумаете.
будем подумать хотя работа в KK уже расписана на миллионе блогов.
Целый мануал. По КК есть целые видеокурсы, в одной статье, думаю, все описать просто не реально.
Ну не мануал конечно но небольшой ликбез для тех кто никогда не видел программы. Я кстати касался этого вопроса в новой статье. Всё уже давно описано но теряется из памяти а когда видишь такое и думаешь — во, slovoeb! вспоминаешь что можно ведь ещё ключи подбирать